
ES 分布式架构原理
面试题:请介绍一下 ES 的分布式架构原理?
面试官心理分析
在搜索领域,Lucene 是最底层的核心库。几年前面试可能还会问“你了解 Lucene 吗?”,但现在已经过时了。现在的互联网项目,绝大多数都是直接使用基于 Lucene 封装的分布式搜索引擎—— Elasticsearch (ES)。
目前 ES 已经成为 Java 分布式系统的标配。所以面试后端或搜索岗位,一定会聊到 ES。如果面试官问“ES 的分布式架构设计是怎样的?”,其实是想考察你对分布式系统的基本理解(数据如何切分、如何保证高可用)。
面试题剖析(基于 ES 8.x 版本)
Elasticsearch 的核心设计理念就是天生分布式。它的底层虽然是基于 Lucene 的,但 Lucene 只是单机的库,而 ES 通过在多台机器上启动多个进程实例,组成了一个高可用的集群。
1. 核心概念:Index (索引) 与 Document (文档)
在 ES 8.x 中,存储数据的基本单位是 Index(索引)。
-
场景举例:假设你要存储订单数据,你应该在 ES 中创建一个名为 orders 的索引。
-
MySQL 类比(关键点):
-
ES Index ≈≈MySQL Table(表)
-
ES Document ≈≈MySQL Row(行)
-
ES Cluster ≈≈ MySQL Database Instance
-
(注意:在 ES 7.0 之前,Index 被类比为 Database,Type 被类比为 Table。但在 ES 8.x 中,Type 概念已被彻底移除,现在的 Index 直接对应 Table。)
-
-
数据结构:你往 Index 里写入的一条数据,叫做 Document(文档),通常是 JSON 格式。一个 Document 包含多个 Field(字段),就像数据库表里的列。
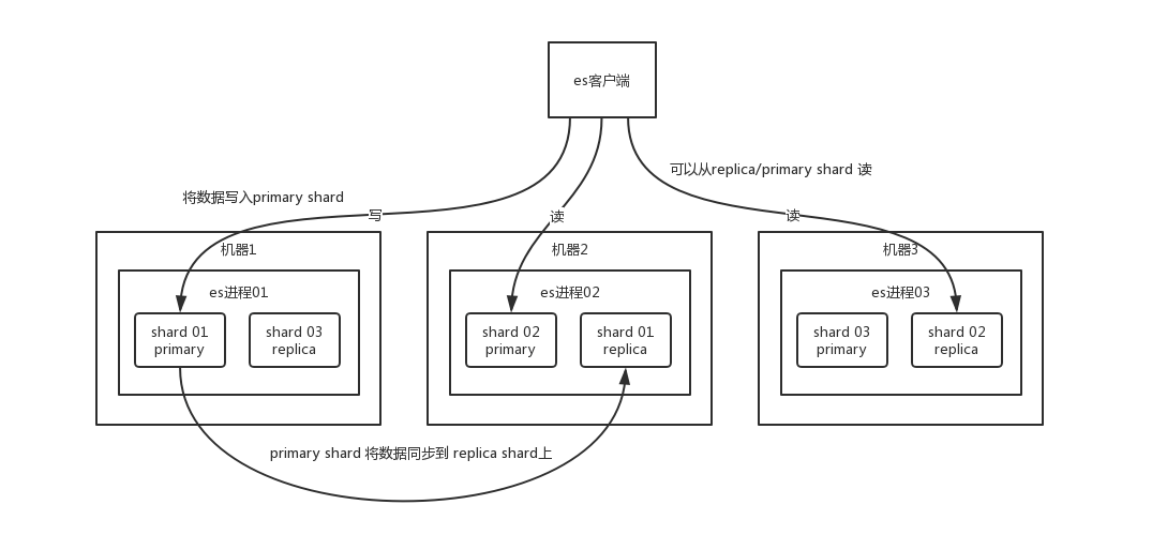
2. 核心架构:Shard (分片) —— 实现横向扩展
如果你的数据量非常大(例如 3TB),单台机器的硬盘存不下,或者单台机器处理搜索请求太慢,怎么办?
ES 引入了 Shard(分片) 的概念:
- 水平切分:一个 Index 中的数据会被切分为多个 Shard。比如 orders 索引有 3TB 数据,我们可以把它切分成 3 个 Shard,每个 Shard 存 1TB。
- 物理本质:每一个 Shard 本质上就是一个独立的、完整的 Lucene Index。
- 好处:
- 横向扩展:Shard 可以分布在集群的多台服务器上。数据量增大了?加机器,把 Shard 迁移过去就行。
- 高性能:搜索时,搜索请求会分发到所有 Shard 上并行执行,最后汇总结果。3 台机器并行搜,肯定比 1 台机器快。
注意:Primary Shard(主分片)的数量在创建索引时设置,设置后通常不能修改(除非重建索引)。ES 7.x/8.x 默认每个索引创建 1 个主分片(不再是早期的 5 个),以避免过度分片带来的资源浪费。
3. 高可用设计:Replica (副本) —— 保证数据不丢
为了防止某台服务器宕机导致 Shard 丢失,ES 引入了 Replica Shard(副本分片)。
- 主从架构:
- Primary Shard (主分片):负责写入数据。
- Replica Shard (副本分片):是主分片的完整拷贝。
- 数据同步:数据写入 Primary Shard 后,会实时(近实时)同步到 Replica Shard。
- 好处:
- 高可用 (HA):如果存放 Primary Shard 的机器宕机了,集群会自动把对应的 Replica Shard 提升为新的 Primary,数据不丢失,服务不中断。
- 提升吞吐量:搜索请求可以在 Primary 和 Replica 上同时执行(读写分离/负载均衡),副本越多,支持的并发查询量越大。
4. 集群运作机制
ES 集群由多个 Node(节点)组成。
- Master Node (主节点):集群会自动选举出一个 Master 节点。它不处理具体的文档增删改查(太累了),只负责“管理工作”:比如维护索引的元数据(有哪些索引、字段定义是什么)、管理集群成员状态(谁掉线了)、分片的分配和调度。
- 故障恢复流程:
- 假设某个非 Master 节点宕机了。
- Master 节点检测到后,发现该节点上的 Primary Shard 没了。
- Master 立即将其他机器上的对应 Replica Shard 提升为 Primary Shard(集群状态变黄,但服务正常)。
- 如果宕机的机器修好重启,或者加入了新机器,Master 会自动分配新的 Replica Shard 到这些机器上,进行数据同步,让集群恢复健康(绿色状态)。
给面试官的加分项(针对 ES 8.x)
如果面试官问:“既然 Type 没了,那我有实物订单和虚拟订单,字段结构不同,该怎么存?”
你的回答:
“在 ES 8.x 中,因为没有 Type 了,针对这种需求有两种主流方案:
- 单索引 + 区分字段:如果字段差异不大,存在同一个 Index 中,加一个 order_type 字段来区分。
- 多索引(推荐):如果字段差异很大(数据稀疏),直接建两个 Index,比如 orders-physical 和 orders-virtual。ES 8 支持通过 orders-* 这种通配符模式同时查询这两个索引,既解决了存储问题,也不影响查询便利性。”
机器坏了,集群还能跑吗?
如果你有这样的疑问:“节点掉线可以用 Replica 顶上,但机器坏了(比如硬盘烧了、主板挂了)不就不行了吗?”
答案是:依然可以运行,只要你有 Replica(副本)。
这里你可能混淆了“节点(Node)”和“机器(Machine)”的关系,或者担心副本也一起丢了。
1. ES 的铁律:鸡蛋不放在同一个篮子里
ES 有一个强制机制:Primary Shard(主分片)和它的 Replica Shard(副本分片)绝对不会放在同一台机器(节点)上。
2. 场景推演:机器坏了会发生什么?
假设你有 3 台机器(Node A, Node B, Node C)。
- 索引情况: 一个 Index,3 个分片,1 个副本。
- 分片分布:
- P0 (主分片0) 在 Node A。
- R0 (副本分片0) 就会自动分配在 Node B 或 Node C(绝对不在 A)。
现在,Node A 这台机器彻底炸了(物理损坏):
- 探测: Master 节点发现 Node A 没心跳了。
- 损失评估: Master 发现 P0 没了(因为它在 Node A 上)。
- 故障转移 (Failover): Master 此时会立刻找到 R0(假设在 Node B 上),把它提升(Promote) 为新的 P0。
- 恢复服务: 此时集群状态变黄(Yellow),因为缺少副本,但数据是完整的,读写依然正常运行。
- 自我修复: 如果 Node A 迟迟不回来,Master 会在 Node C 上再复制一个新的 R0,让集群重新变绿(Green)。
结论:
除非你所有存有该数据副本的机器同时坏了(比如机房断电、地震),否则单台机器物理损坏,ES 是完全能扛住的。这就是分布式的意义。
协调节点(Coordinating Node)的流程
我以前会认为:
用户 -> 发送请求 -> ARS -> 协调节点 -> 分发给 Shard -> 汇总 -> 返回用户
这部分理解 90% 是对的,但在 ARS 的位置和具体步骤上可以更专业一点(面试加分项)。
我们可以把这个过程比喻成**“项目经理外包工作”**。
纠正一个小概念:ARS (Adaptive Replica Selection)
ARS 不是把请求发送到协调节点的东西。
- 用户(Client/浏览器/Java代码) 发送请求给集群中的任意一个节点(通常通过负载均衡器)。
- 这个收到请求的节点,就临时变成了“协调节点(Coordinating Node)”(也就是项目经理)。
- ARS 是在这个节点内部运行的逻辑: 当协调节点决定要去请求数据时,发现 P0 和 R0 都有数据,它该选谁呢?ARS 算法会根据节点的负载、响应速度,智能选择一个最快的副本去查。
满分回答:ES 搜索的“查询两阶段”(Query Then Fetch)
面试时,不要只说“收集数据”,要拆解成两个阶段,显得你懂原理:
第一阶段:Query Phase(查询阶段 - 只要 ID)
- 接收: 协调节点收到你的搜索请求(比如搜“手机”)。
- 分发(Scatter): 协调节点根据路由公式,把请求转发给索引的所有分片(每个分片选一个副本,利用 ARS 选择最优的)。
- 局部检索: 每个分片在自己本地查询,找到匹配的文档,但只取 doc_id 和 _score(打分),不取完整数据。
- 初步返回: 每个分片把找到的 doc_id 和分数列表(比如前 10 条)返回给协调节点。
- 全局排序: 协调节点拿到所有分片的结果(假设 5 个分片,每个给 10 条,一共 50 条),在内存中进行全局排序,选出最终的 Top 10。
第二阶段:Fetch Phase(获取阶段 - 要完整数据)
- 精确定位: 协调节点手里现在只有 Top 10 的 doc_id,没有具体内容(_source)。
- 抓取(Gather): 协调节点根据这 10 个 doc_id,去对应的分片上把完整的 JSON 数据(_source)拉取回来。
- 最终返回: 拼装好数据,返回给客户端。


