
搜索引擎
搜索引擎
Lucene 和 ES 的前世今生
Lucene 是最先进、功能最强大的搜索库。如果直接基于 Lucene 开发,非常复杂,即便写一些简单的功能,也要写大量的 Java 代码,需要深入理解原理。
ElasticSearch 基于 Lucene,隐藏了 lucene 的复杂性,提供了简单易用的 RESTful api / Java api 接口(另外还有其他语言的 api 接口)。
- 分布式的文档存储引擎
- 分布式的搜索引擎和分析引擎
- 分布式,支持 PB 级数据
如果把搜索引擎比作一辆赛车,那么 Lucene 就是这辆车的引擎(核心动力,复杂、裸露),而 Elasticsearch 就是整车(包含了引擎,并且装配了方向盘、仪表盘、车轮,让你直接能开)。
ES 的核心概念
Near Realtime
近实时,有两层意思:
- 从写入数据到数据可以被搜索到有一个小延迟(大概是 1s)
- 基于 ES 执行搜索和分析可以达到秒级
为什么是 1 秒?因为数据写入 ES 后,先进入内存 Buffer,此时还搜不到。ES 默认每隔 1 秒执行一次 Refresh 操作,把 Buffer 里的数据生成一个新的 Segment(段),这时数据才能被索引到。这 1 秒就是 refresh_interval。
Cluster 集群
集群包含多个节点,每个节点属于哪个集群都是通过一个配置来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常。
Node 节点
Node 是集群中的一个节点,节点也有一个名称,默认是随机分配的。默认节点会去加入一个名称为 elasticsearch 的集群。如果直接启动一堆节点,那么它们会自动组成一个 elasticsearch 集群,当然一个节点也可以组成 elasticsearch 集群。
Document & field
文档是 ES 中最小的数据单元,一个 document 可以是一条客户数据、一条商品分类数据、一条订单数据,通常用 json 数据结构来表示。每个Index下可以存储多条document。一个 document 里面有多个 field,每个 field 就是一个数据字段。
1 | { |
Index
索引包含了一堆有相似结构的文档数据,比如商品索引。一个索引包含很多 document,一个索引就代表了一类相似或者相同的 document。
Type
(在现在的 Elasticsearch(7.x 和 8.x 版本)开发中,Type 已经被废弃并移除。)
类型,每个索引里可以有一个或者多个 type,type 是 index 的一个逻辑分类,比如商品 index 下有多个 type:日化商品 type、电器商品 type、生鲜商品 type。每个 type 下的 document 的 field 可能不太一样。
类比
ES Cluster (集群) ≈≈MySQL Database(数据库实例)
ES Index ≈≈MySQL Table(表)
ES Document ≈≈MySQL Row(行)
Shard (分片)
单台机器无法存储海量数据。ES 类似于把一张巨大的“表”水平切分,切成几块,每一块就是一个 Shard。
- 作用:横向扩展。比如你有 3TB 数据,切成 3 个 Shard,每个 Shard 1TB,就可以分散存在 3 台服务器上。
- 本质:每个 Shard 就是一个独立的、功能完整的 Lucene Index。
注意:
- ES 说的 Index(索引): 是一个逻辑概念。比如“商品索引”,它是一个巨大的集合,包含了 1 亿条数据。
- Lucene 说的 Index(索引): 是一个物理概念。它是硬盘上实实在在的一堆文件,是 Lucene 这个库能够管理的最小单元。
“Shard 是 Lucene Index” 的意思就是:
Elasticsearch 也是个“二道贩子”,它自己并不直接处理落盘的数据,而是把数据切分成一块一块的(Shard),然后每一块都交给一个 Lucene 实例去管理。
通俗类比:图书馆与书架
假设你要建一个**“国家图书馆”(ES Index)**,里面有 1 亿本书。
问题:
如果只用一个房间(一台机器)存这 1 亿本书,房间放不下,而且找书的时候,几万人挤进一个房间查,效率太慢。
解决方案(Sharding):
你决定把这 1 亿本书切分到 5 个分馆(Shard) 去存放。
- 分馆 1:放编号 0-2000万 的书
- 分馆 2:放编号 2000万-4000万 的书
- …
重点来了(Shard = Lucene Index):
每个“分馆”,其实就是一个完整、独立的小型图书馆。
- 每个分馆都有自己的管理员(Lucene)。
- 每个分馆都有自己的目录系统(倒排索引文件)。
- 每个分馆都可以独立进行书籍的入库和查询。
当你去搜索时:
- 你在这个“国家图书馆”(ES Index)的门口喊一声:“我要找《哈利波特》!”
- 总台(ES Node)会把这个命令通过对讲机广播给这 5 个分馆的管理员(Lucene)。
- 这 5 个分馆的管理员(Lucene)同时在自己的分馆里找。
- 找完后,大家把结果汇总给总台,总台再给你。
技术层面的解释(面试怎么说)
如果在面试中,面试官问到 Shard 的底层原理,你可以这样回答:
- Lucene 的局限性: Lucene 是一个 Java 库,它本身是不支持分布式的。它就像一个单机的软件,只能管理本地磁盘上的一组文件。这组文件在 Lucene 的术语里就叫“Index”。
- ES 的包装: Elasticsearch 为了实现分布式(让多台机器协同工作),在逻辑上弄了一个“ES Index”的概念,然后把数据切分成多个 Shard。
- 一一对应关系: 每一个 ES 的 Shard,在物理底层,就是一个完整的 Lucene Index。 这意味着每一个 Shard 都有自己独立的倒排索引文件,都可以独立执行搜索。
为什么要这么设计?(好处)
- 并行计算:因为每个 Shard 都是一个独立的搜索引擎(Lucene Index),所以当你查 ES 时,这 5 个 Shard 是同时在工作的。速度变成了原来的 5 倍。
- 水平扩展:因为 Lucene 是独立的,我可以把 Shard 1 放在服务器 A,Shard 2 放在服务器 B……这样就可以无限扩容了。
总结
当你看到 “Shard 是 Lucene Index” 时,你就理解为:
Shard 是一个物理上独立存在的、最小化的、完整的搜索引擎实例。
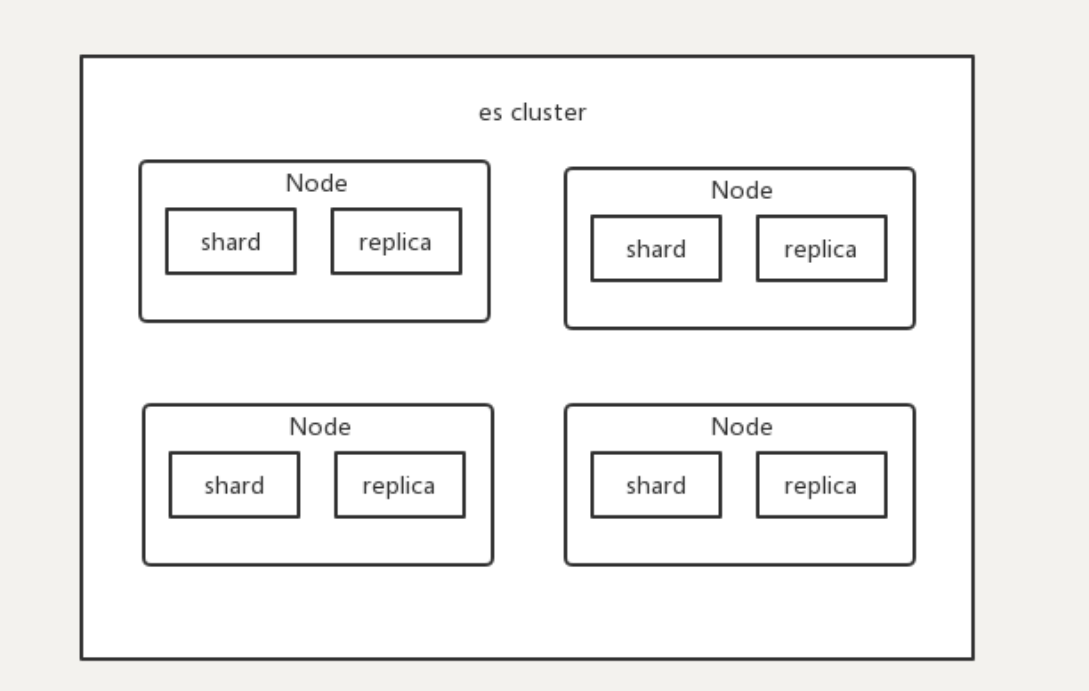
Replica (副本)
为了防止某个服务器挂了导致 Shard 丢失,ES 允许给 Shard 做备份,这就是 Replica。
- 作用:
- 高可用:主分片挂了,副本分片马上升级为主分片,保证数据不丢。
- 高性能:查询时,可以在主分片和副本分片上同时查,分担查询压力(提升 QPS)。
- 配置:
- Primary Shard:建立索引时设置,一旦设置一般不能修改(除非重建索引)。
- Replica Shard:随时可以修改数量。
- 默认值:ES 7.x 以后,默认是 1 主 1 副(共 2 个分片)。
Q1: 什么是倒排索引(Inverted Index)?
- 通俗解释:
- 正排索引(MySQL): 根据 ID 找内容。(ID 1 -> “iPhone X”)
- 倒排索引(ES): 根据关键词找 ID。(“iPhone” -> ID 1, ID 5, ID 8…)
- 作用: 它是 ES 搜索快的最核心原因。
Q2: Shard 和 Replica 的区别?
- Shard(主分片): 负责写。数据是切分开存的,为了水平扩展(存更多数据)。
- Replica(副本分片): 负责读(和备份)。数据是完整的拷贝,为了高可用(防宕机)和高并发(读得更快)。
Q3: ES 写入数据和搜索数据的流程是怎样的?
- 写: 只能写在 Primary Shard,然后同步给 Replica。
- 读: Primary 和 Replica 都可以读,ES 会自动做负载均衡。
更详细可以查看这个网站中其他系列文章~


