
ES 读写原理
深入底层:ES 8.x 的读写原理与倒排索引
这篇文章的内容非常硬核,是面试中用来区分“调包侠”和“研发工程师”的分水岭。
面试题
ES 写入数据的工作原理是什么?查询数据的工作原理是什么?底层的 Lucene 和倒排索引了解吗?
面试官心理分析
这个问题是问 “黑盒” 里的东西。
平时我们只管调 API PUT 和 GET,但如果不懂底层,一旦遇到写入慢、数据丢了、搜索不准等问题,你就两眼一抹黑。面试官想知道你是否理解数据在内存和磁盘间是如何流转的,以及 ES 是如何保证高可用和近实时的。
1. 核心大前提:副本去哪了?
在 ES 的分布式架构中,有一个铁律:同一个 Shard 的 Primary(主分片)和 Replica(副本分片)绝对不会存放于同一台机器(节点)上。
- 为什么? 如果主分片和副本分片都在机器 A,那机器 A 一旦宕机,主副全没,数据就彻底丢失了。
- 怎么做? ES 会自动实施“反亲和性(Anti-affinity)”策略,强制把副本分散到其他机器。如果集群只有 1 台机器,副本将无法分配(Unassigned),集群状态变黄。
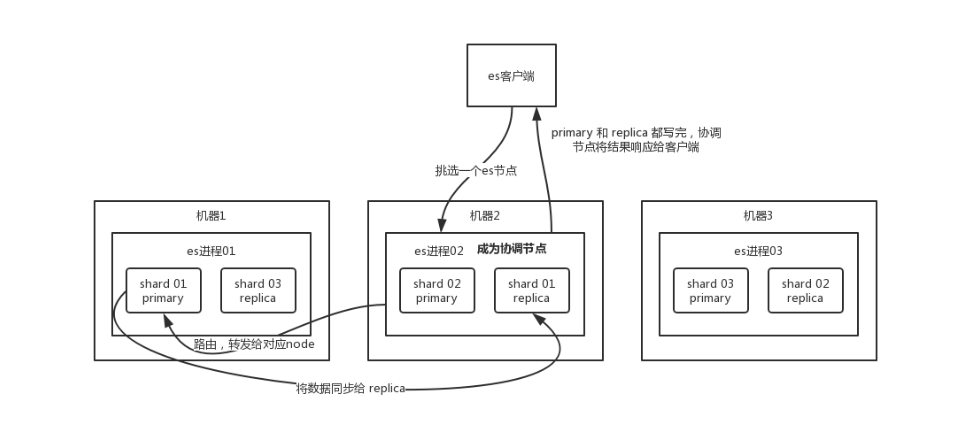
2. ES 写数据过程(Write Path)
场景:客户端发起请求,新增或修改一条数据。
- 协调节点(Coordinating Node)接收请求:
客户端可以向集群中任意节点发送请求,该节点就充当“协调节点”。 - 路由(Routing):
协调节点根据hash(_id) % primary_shard_num计算出该数据属于哪个分片(比如 Shard 0)。 - 转发给主分片:
协调节点查表找到 Shard 0 的 Primary Shard 所在的节点,将请求转发过去。 - 主分片写入:
Primary Shard 处理写入请求,写入成功后。 - 并发同步副本:
Primary Shard 并行将数据发送给所有的 Replica Shard。 - 响应客户端:
当所有的(或者满足wait_for_active_shards配置的)Replica Shard 都报告写入成功,Primary Shard 向协调节点报告成功,协调节点再返回给客户端“写入成功”。
3. ES 读数据过程(Read / Get Path)
场景:客户端根据 ID 查询一条数据(GET /index/_doc/1)。
- 协调节点接收:客户端发请求到任意节点(协调节点)。
- 路由计算:协调节点计算 hash,知道数据在 Shard 0。
- 智能负载均衡(ARS):
- 老版本:简单的随机轮询(Round-Robin)。
- ES 7/8 新特性:ARS (Adaptive Replica Selection)。协调节点会记录每个节点的健康状况和响应速度,智能选择一个响应最快、负载最低的副本(或者是主分片)来查询。
- 返回结果:持有数据的节点将文档返回给协调节点,协调节点转发给客户端。
4. ES 搜索数据过程(Search Path)
场景:全文检索(比如搜索关键词 “Java”)。
这是一个两阶段过程:Query Then Fetch。
第一阶段:Query Phase(查询)
- 协调节点将搜索请求广播到所有的分片(每个分片随机选一个副本或主分片)。
- 每个分片在本地进行搜索,但不返回完整数据,只返回Doc Id 和 排序打分值。
- 协调节点汇总所有分片返回的 ID 和分数,进行全局排序、分页,筛选出最终要返回的那一页数据的 ID。
第二阶段:Fetch Phase(取数)
- 协调节点拿着筛选出来的 ID,去对应的分片上拉取完整的 Document 数据(_source 内容)。
- 协调节点拼装最终结果,返回给客户端。
5. 写数据底层原理(Buffer, Translog, Segment)
这是面试最爱问的细节,涉及数据会不会丢!
ES 的写入不是直接写硬盘,而是经过了复杂的内存缓冲。
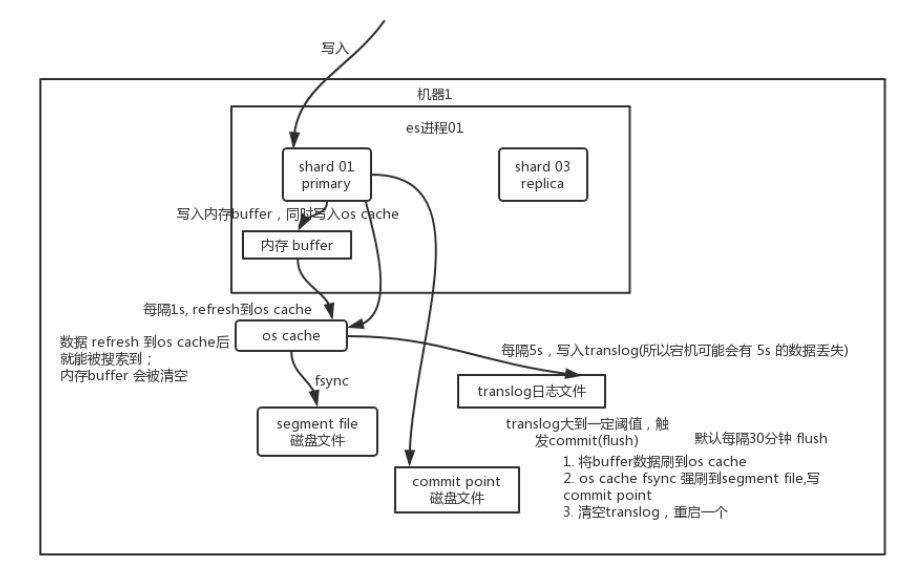
核心组件
- Memory Buffer:内存缓冲区,写入的数据先放这。
- OS Cache:操作系统的文件系统缓存。
- Translog:预写日志(Write Ahead Log),用于灾难恢复。
- Segment File:Lucene 的倒排索引文件(磁盘/OS Cache 中)。
详细步骤
- 写入 Buffer 和 Translog:
数据先写入 Memory Buffer,同时追加写入 Translog 文件(防止内存断电丢失)。此时数据搜索不到。 - Refresh(默认 1秒):
- 每隔 1 秒,ES 将 Buffer 里的数据刷新到 OS Cache 中,并生成一个新的 Segment。
- 关键点:一旦进入 OS Cache,数据就可以被搜索到了。
- 这就是为什么 ES 被称为“近实时(Near Realtime)”搜索,因为有 1 秒延迟。
- Refresh 后,清空 Memory Buffer,但 Translog 保留。
- Flush(默认 30分钟 或 Translog 过大):
- 随着时间推移,Translog 越来越大。触发 Flush 操作。
- 执行 Commit:强行将 OS Cache 里的所有 Segment fsync(物理落盘)到磁盘。
- 清空 Translog:因为数据已经安全落盘,旧日志可以删了。
关于丢数据(面试加分项)
- 问:ES 会丢数据吗?
- 答:可能会,但只有 5 秒。
Translog 默认每 5 秒(异步)刷一次盘。如果机器在数据写入 Buffer 且 Translog 还没刷盘的那几秒宕机,内存里的数据就没了。- 怎么解决? 金融级业务可以把 Translog 设置为
request(同步),每次写入必须落盘才返回成功,但性能会由于频繁 IO 而下降。
- 怎么解决? 金融级业务可以把 Translog 设置为
6. 删除/更新原理
Lucene 的 Segment 文件是**不可变(Immutable)**的。
- 删除:不是真删,而是写一个
.del文件,标记某个 Doc ID 为“已删除”。搜索时虽然能查到,但在返回前会被过滤掉。 - 更新:本质是 Delete + Insert。先在
.del文件里标记旧版本删除,然后写入一个新版本的 Document。 - Segment Merge:后台线程会定期把很多小的 Segment 合并成大的,这时候才会真正物理清除那些被标记删除的数据。
7. 底层 Lucene 与倒排索引
Elasticsearch 是汽车,Lucene 是引擎。ES 的 Shard 本质上就是一个 Lucene Index。
倒排索引 (Inverted Index)
正排索引:ID -> 内容 (MySQL 的主键查询)。
倒排索引:关键词 -> ID列表 (搜索引擎的核心)。
举例:
文档 A (ID:1): “Google Map”
文档 B (ID:2): “Google Search”
倒排索引结构:
| Term (关键词) | Doc IDs (倒排表) |
|---|---|
| [1, 2] | |
| Map | [1] |
| Search | [2] |
- 词项字典 (Term Dictionary):记录所有关键词,通常用 B+树或 FST (Finite State Transducers) 存储,查询极快。
- 倒排表 (Posting List):记录包含该词的文档 ID、出现频率、位置等。
面试总结:
当你搜 “Google” 时,Lucene 直接去字典里查,瞬间找到 ID [1, 2],而不需要像 MySQL LIKE %Google% 那样全表扫描。这就是 ES 快的原因。


